1,jieba分词及字典加载、未登录词处理,正则结合词典解决单单加载词典也无法解决的问题。
措施一:加载词典,然后调整加载的字典的词频。有些词还是会分布准确,可以分词后查看分词结果,将没分准的词拷贝到词典中,扩展词典。
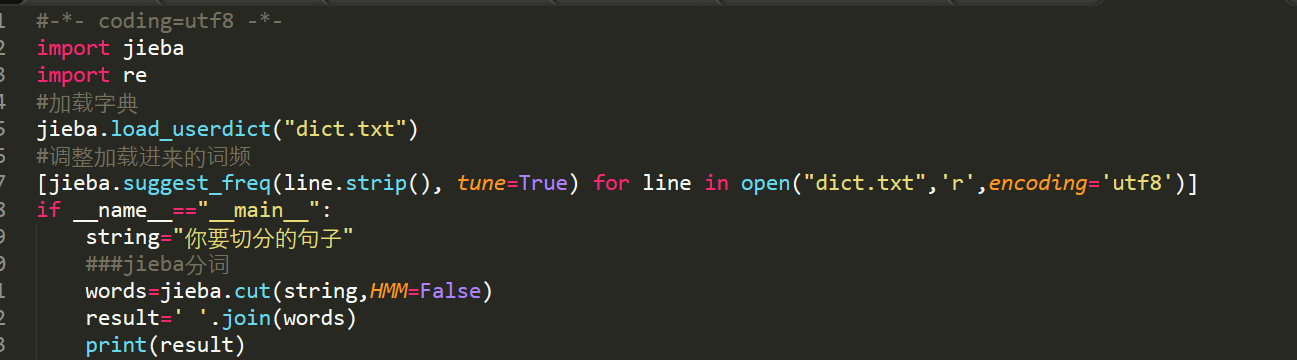
措施二:结合措施一,处理有些在字典里有也无法准确分出的词的处理。例如III期,3期,35.3%等,我们需要结合正则表达式来处理。(思想:显示正则匹配没一行句子,匹配到那些特殊的词,例如3期、III期等,用“FLAGS”来代替,然后进行分词,再join这些词以空格或者‘/’来区分每一个词。再判断‘FLAGS’是否在已分好词的没一行中,如果某行含有‘FLAGS’,以"FLAGS"来分割,split(’FLAGS‘)——这样每一行中含有那些特殊词的位子就会在列表里没有了,
(注:此时的那些词都在我们利用正则匹配到的另一个列表中)。此时我们会有两个列表:一个是没有我们要匹配’III期,3期,‘这些词的列表,另一个是我们利用正则恰恰收集到这些词的列表。)
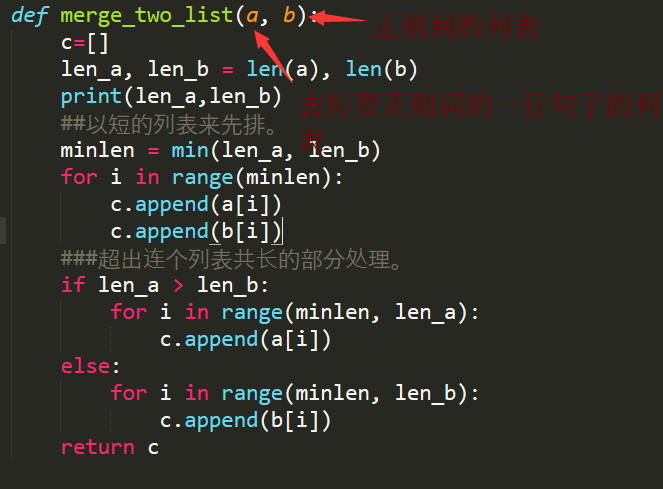
有了两个列表,我们就可以想办法写一个函数再将这两个列表安顺整合成一个列表,这样我们就可以完美的完成了分词了。
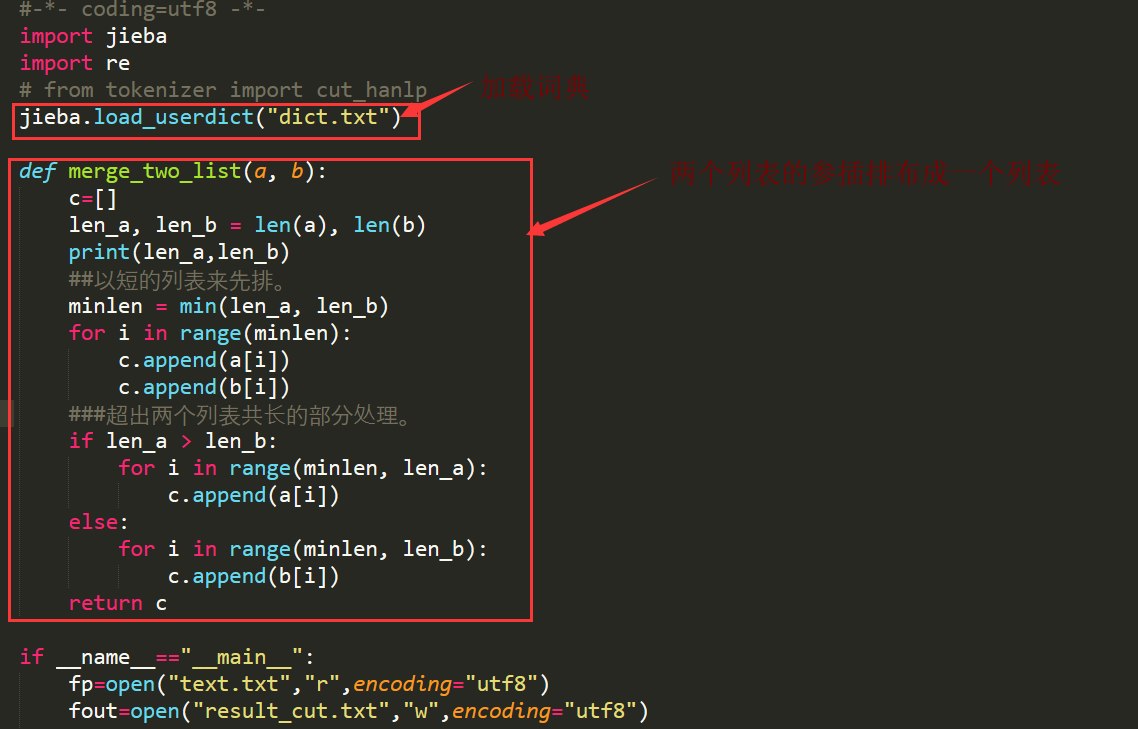
两个列表排序合并解析:
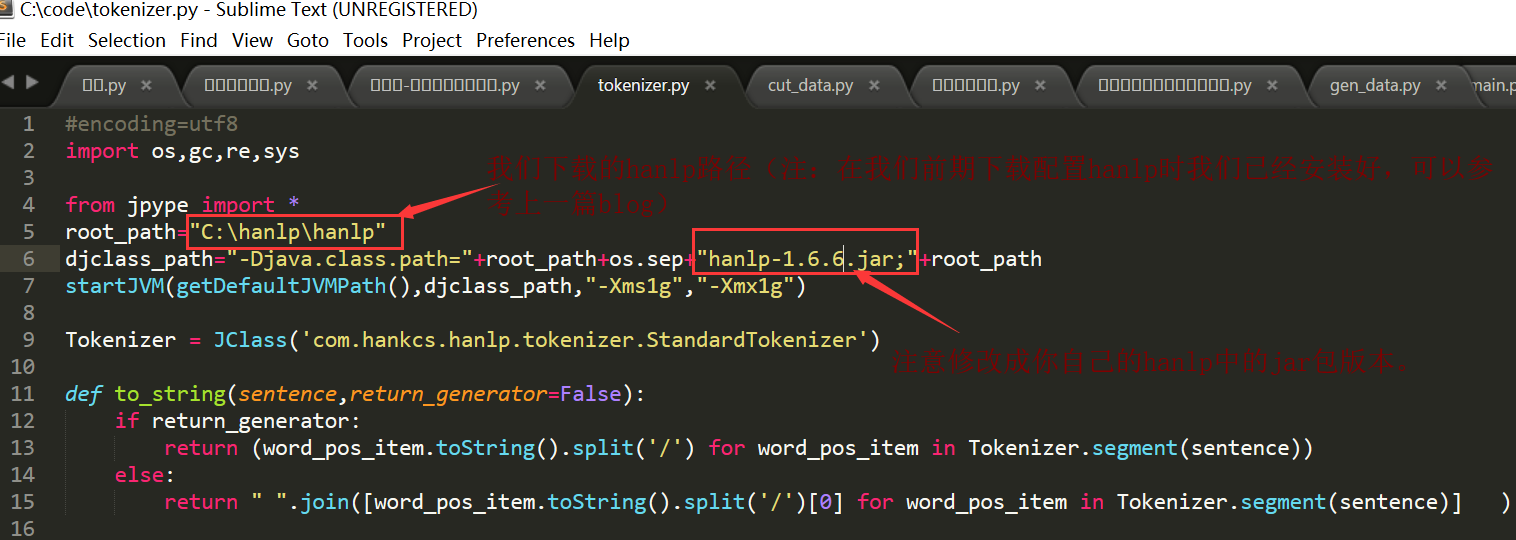
2,hanlp的使用以及hanlp也可以加载词典的使用。——hanlp是按照加载词典词的顺序要分词。
2.1hanlp的分词程序所引入的一个文件:tokenizer.py

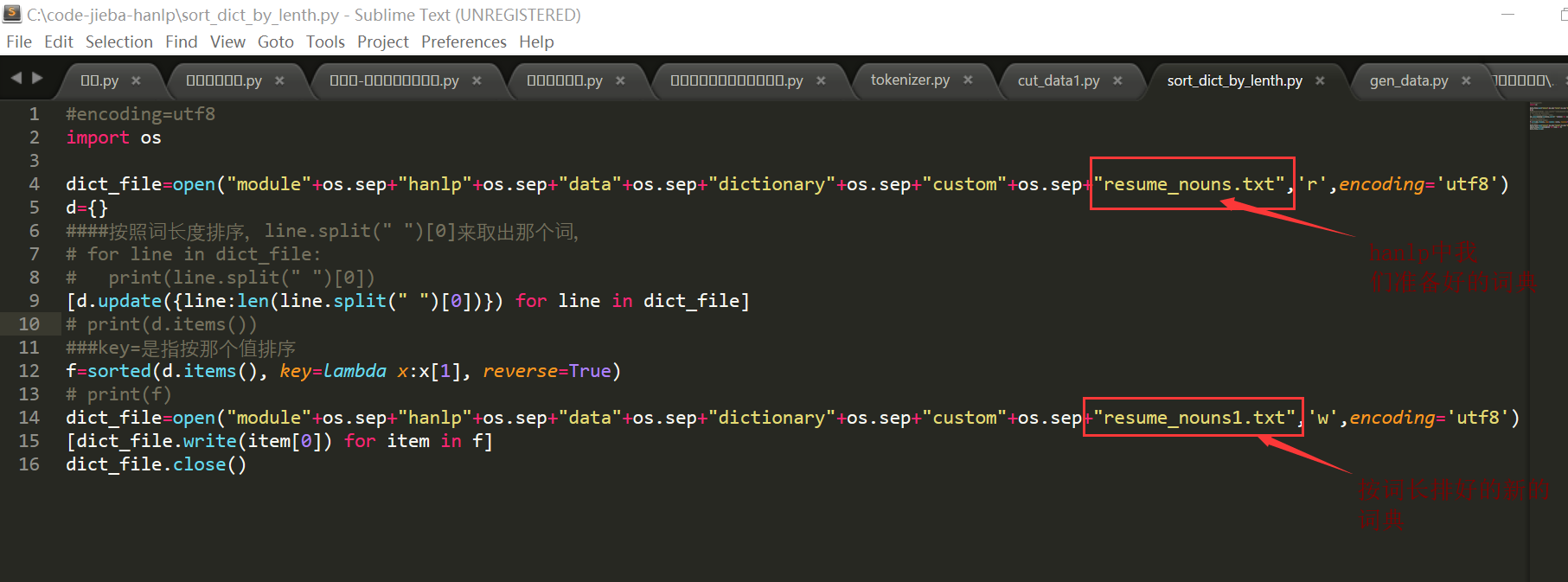
2.2:有时候我们的分词,希望偏长词来匹配:例如:数据库设计、数据库,都是我们词典中的词,但是我们希望能分成’数据库设计‘而不是’数据库 /设计‘,那么我们就需要对我们的词典进行一个按词的长度来排序,因为hanlp是按照加载词典词的先后顺序来分词的。对我们词典中的词进行按词长来排序sort_dict_by_length.py :
![]()
使用hanlp分词就很简单了。
from tokenizer import cut_hanlp
