接着上一篇的CRF使用。
在我们运用测试集的获得如下样式之后,就可以对我们的模型进行效果评估的了,评估以三个
准确率、召回率、F值

字母B的准确率,就是B字母在最右边那列和中间那列一起出现的次数(也就是标正确的B出现的次数)除以 B字母在最右边那列出现的次数(即机器标出B的次数)。计算字母B的召回率,就是B字母在最右边那列和中间那列一起出现的次数(也就是标正确的B出现的次数)除以 B字母在中间那列出现的次数。计算字母B的F值,这个就直接套公式了,把你上面刚刚算出的准确率*召回率*2/(准确率+召回率)就得到了。
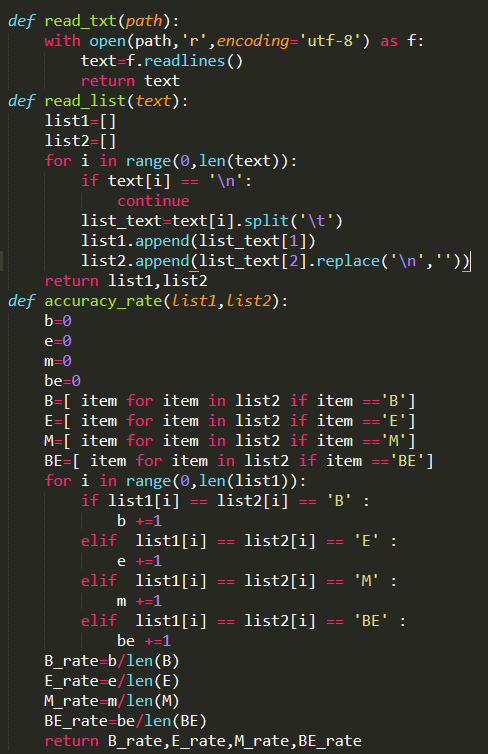
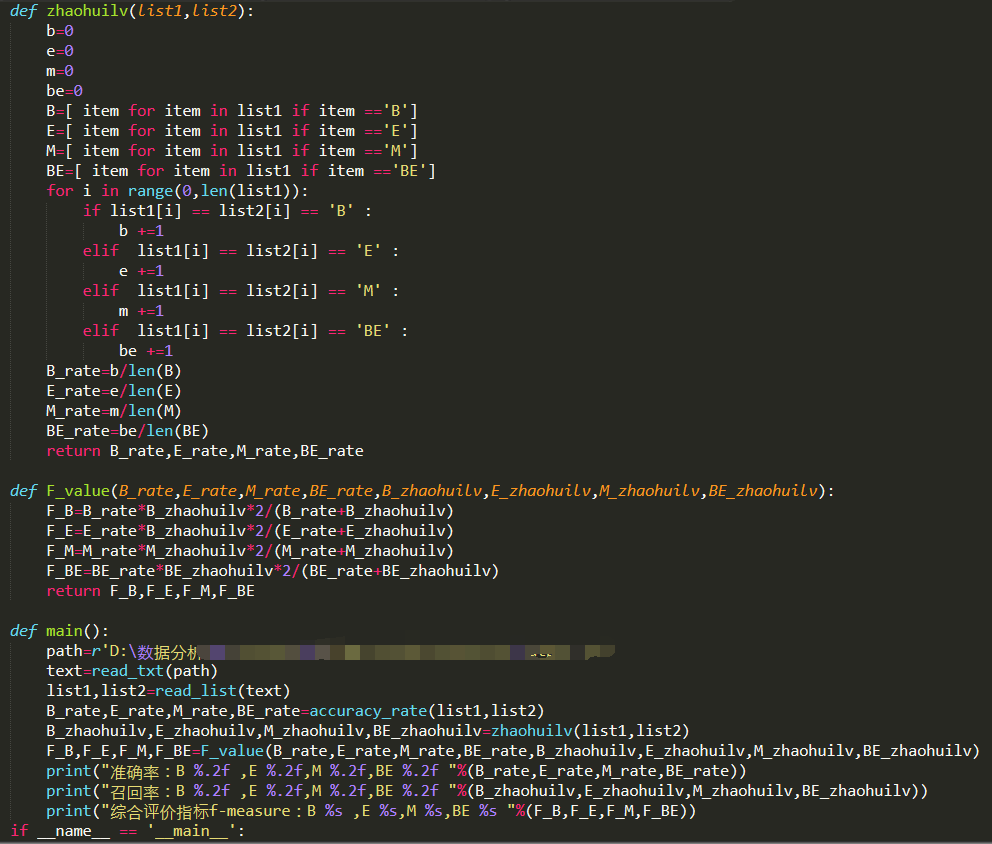
(本人比较懒,就将之前分词做的评估代码附上了,其实都是一样的)
注:这是初步评估模型的好坏,实际上后期的任务中可能会要求将整个词都识别出来才算机器识别对了。
提供一个思路:words = re.split("B|E",line)
批处理:
生成确定model后,在进行测试时或当确定了模型后,新的语料来应用。——就要进行批处理,因为手动一个一个太慢了。
具体看下图
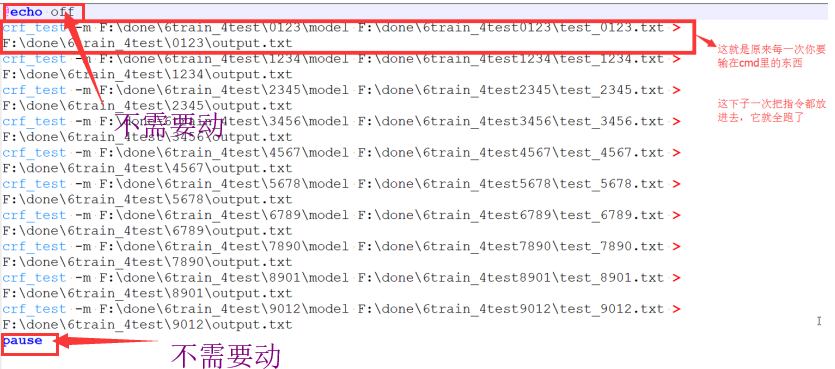
写一个txt文件,里面的内容写成和上图类似的,这个图片中开头和结尾不需要改,他们中间的换成你的指令(你可以写一段代码生成这么多长得差不多的语句,这个大家肯定能够写出来)。然后把你的txt后缀改成.bat,把这个bat文件放在你的crf++tools里,双击这个.bat文件,会弹出cmd的黑色框,cmd就自己跑起来了。